概述
紧凑区块中继,BIP152,是一种减少用于将新区块传播到完整节点的带宽量的方法。
摘要
使用简单的技术,当完整节点已经共享大部分相同的内存池内容时,可以减少将新区块传播到完整节点所需的带宽量。节点向接收节点发送紧凑区块“草图”。这些草图包含以下信息
- 新区块的 80 字节头部
- 缩短的交易标识符 (txid),旨在防止拒绝服务 (DoS) 攻击
- 发送节点预测接收节点尚未拥有的某些完整交易
然后,接收节点尝试使用接收到的信息和其内存池中已有的交易来重建整个区块。如果仍缺少任何交易,它将向发送节点请求这些交易。
这种方法的优势在于,在最佳情况下,交易只需要发送一次——当它们最初广播时——从而大幅减少整体带宽。
此外,紧凑区块中继提案还提供了第二种操作模式(称为高带宽模式),其中接收节点要求其一些节点在未经事先请求许可的情况下直接发送新区块,这可能会增加带宽(因为两个节点可能会尝试同时发送相同的区块),但进一步减少了区块到达所需的时间(延迟)在高带宽连接上。
下图显示了节点当前发送区块的方式与紧凑区块中继的两种操作模式的比较。节点 A 时间线上灰色的框表示它执行验证的时期。
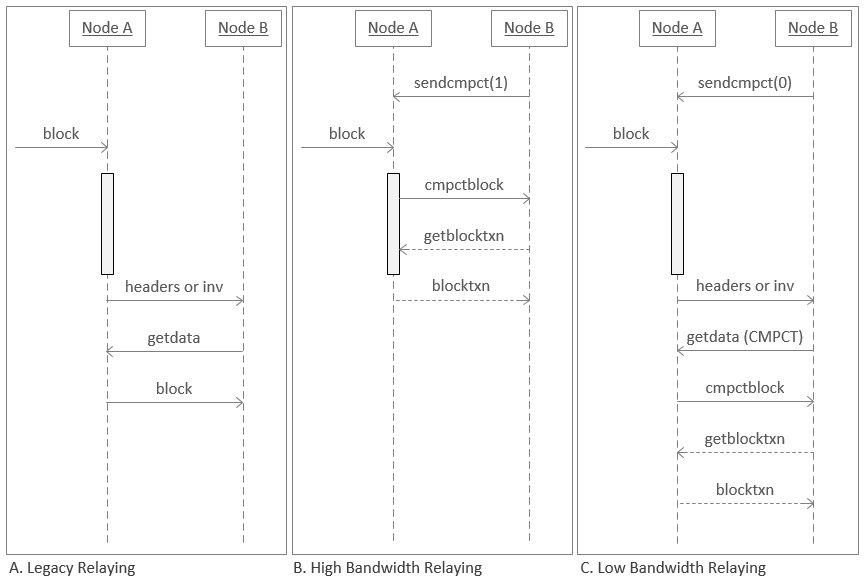
-
在传统中继中,区块由节点 A 验证(灰色条),然后节点 A 向节点 B 发送
inv消息,请求许可发送区块。节点 B 回复getdata请求区块,节点 A 发送区块。 -
在高带宽中继中,节点 B 使用
sendcmpt(1)(发送紧凑)告诉节点 A 它希望尽快收到区块。当新区块到达时,节点 A 执行一些基本验证(例如验证区块头部),然后自动开始将头部、缩短的 txid 和预测缺失的交易(如上所述)发送到节点 B。节点 B 尝试重建区块并请求任何仍缺少的交易(getblocktxn),节点 A 发送这些交易(blocktxn)。在后台,两个节点在将其添加到其本地区块链副本之前完成对区块的完整验证,保持与以前相同的完整节点安全性。 -
在低带宽中继中,节点 B 使用
sendcmpt(0)告诉节点 A 它希望尽可能减少带宽使用。当新区块到达时,节点 A 会完全验证它(因此它不会中继任何无效区块)。然后它询问节点 B 是否想要该区块(inv),以便如果节点 B 已经从另一个节点接收到该区块,它可以避免再次下载它。如果节点 B 确实想要该区块,它会以紧凑模式请求它(getdata(CMPCT)),节点 A 会发送头部、短 txid 和预测缺失的交易。节点 B 尝试重建区块,请求任何仍缺少的交易,节点 A 发送这些交易。然后节点 B 通常完全验证区块。
这方面的一些有用基准是什么?
接收节点可以使用 9KB 的区块草图重建平均 1MB 的完整区块公告,加上区块中不在接收节点内存池中的每笔交易的开销。观察到的最大区块草图在 20KB 左右。
在“高带宽”模式下进行现场实验并让节点预填充多达 6 笔交易时,我们可以预期看到超过 90% 的区块会立即传播,而无需请求任何缺失的交易。即使没有预填充任何交易(除了创世区块),实验表明我们也可以看到超过 60% 的区块立即传播,其余的需要额外的完整网络往返行程。
由于预热节点的内存池和区块之间的差异很少超过 6 笔交易,这意味着紧凑区块中继可以显著减少所需的峰值带宽。
如何选择预期缺失的交易以立即转发?
为了减少初始实现中需要审查的事项数量,只会预先发送创世区块交易。
但是,在所描述的实验中,发送节点使用了一个简单的公式来选择要发送的交易:当节点 A 接收到一个区块时,它会检查该区块中哪些交易不在其内存池中;这些是它预测其节点没有的交易。理由是(在没有其他信息的情况下),您不知道的交易可能也是您的节点不知道的交易。使用这种基本启发式方法,观察到了很大的改进,说明很多时候最简单的解决方案是最好的。
快速中继网络如何融入其中?
快速中继网络Fast Relay Network (FRN) 由两部分组成
-
当前快速中继网络中精心挑选的节点集
-
快速区块中继协议 (FBRP)
FRN 中精心挑选的节点集已精心挑选,全球范围内的最小中继是首要任务。这些节点的故障会导致大量浪费的哈希算力和潜在的进一步挖矿集中化。如今,绝大多数挖矿哈希算力都连接到此网络。
最初的 FBRP 是参与节点之间相互通信区块信息的方式。节点跟踪它们彼此发送的交易,并根据此知识中继区块差异。该协议对于新区块的一对一服务器-客户端通信几乎是最佳的。最近,一种基于 UDP 和前向纠错 (FEC) 的协议,名为 RN-NextGeneration,已部署供矿工测试和使用。然而,这些协议需要一个连接性不佳的中继拓扑结构,并且比更通用的点对点网络更脆弱。使用紧凑区块在协议级别的改进将缩小精心挑选的节点网络与一般点对点网络之间的性能差距。点对点网络的增强鲁棒性和区块传播速度将在网络未来的发展中发挥作用。
这是否扩展了比特币?
此功能旨在为节点节省峰值区块带宽,减少可能降低最终用户互联网体验的带宽峰值。但是,正如以下视频中所述,挖矿的集中化压力在很大程度上是由于区块传播的延迟造成的。紧凑区块版本 1 主要并非旨在解决此问题。
https://www.youtube.com/embed/Y6kibPzbrIc
预计矿工将继续使用快速中继网络Fast Relay Network,直到开发出更低延迟或更健壮的解决方案。但是,对基本点对点协议的改进将提高 FRN 故障情况下的鲁棒性,并且可能会减少专用中继网络的优势,使其不值得运行。
此外,使用紧凑区块的第一版进行的实验和收集的数据将为我们期望与 FRN 更具竞争力的未来改进的设计提供信息。
谁受益于紧凑区块?
-
想要中继交易但互联网带宽有限的完整节点用户。如果您只想在仍然将区块中继到节点的同时尽可能节省带宽,则从 Bitcoin Core v0.12 开始就已经提供了
blocksonly模式。仅区块模式仅在交易包含在区块中时才接收交易,因此没有额外的交易开销。 -
整个网络。减少点对点网络上的区块传播时间可以创建一个更健康的网络,并具有更好的基线中继安全裕度。
紧凑区块传播的编码、测试、审查和部署时间表是什么?
紧凑区块的第一版已分配给BIP152,具有工作实现,并且正在由开发人员社区积极测试。
- BIP152:https://github.com/bitcoin/bips/blob/master/bip-0152.mediawiki
- 参考实现:https://github.com/bitcoin/bitcoin/pull/8068
如何将其改编为更快的点对点中继?
可以对紧凑区块方案进行额外的改进。这些与 RN-NG 相关,并且有两方面
-
首先,用 UDP 传输替换区块信息的 TCP 传输。
-
其次,通过使用前向纠错 (FEC) 代码处理丢弃的数据包并预先发送缺失的交易数据。
UDP 传输允许服务器发送数据并由客户端尽可能快地消化,而无需担心间歇性丢弃的数据包。客户端宁愿接收乱序的数据包以尽快构建区块,但 TCP 不允许这样做。
为了处理丢弃的数据包并从多个服务器接收非冗余的区块数据,将使用 FEC 代码。FEC 代码是一种将原始数据转换为冗余代码的方法,只要一定百分比的数据包到达其目的地,就可以实现无损传输,其中所需数据仅略大于数据的原始大小。
这将允许节点在收到区块后立即开始发送区块,并允许接收者同时重建从多个节点流式传输的区块。所有这些工作都继续建立在已完成的紧凑区块工作之上。这是一个中期扩展,开发正在进行中。
这个想法新颖吗?
使用布隆过滤器(例如在BIP37 过滤区块中使用的过滤器)更有效地传输区块的想法是在几年前提出的。它也由 Pieter Wuille (sipa) 在 2013 年实现,但他发现开销导致传输速度变慢。
[#bitcoin-dev, public log (excerpts)]
[2013-12-27]
09:12 < sipa> TD: i'm working on bip37-based block propagation
[...]
10:27 < BlueMatt> sipa: bip37 doesnt really make sense for block download, no? why do you want the filtered merkle tree instead of just the hash list (since you know you want all txn anyway)
[...]
15:14 < sipa> BlueMatt: the overhead of bip37 for full match is something like 1 bit per transaction, plus maybe 20 bytes per block or so
15:14 < sipa> over just sending the txid list
[2013-12-28]
00:11 < sipa> BlueMatt: i have a ~working bip37 block download branch, but it's buggy and seems to miss blocks and is very slow
00:15 < sipa> BlueMatt: haven't investigated, but my guess is transactions that a peer assumes we have and doesn't send again
00:15 < sipa> while they already have expired from our relay pool
[...]
00:17 < sipa> if we need to ask for missing transactions, there is an extra roundtrip, which makes it likely slower than full block download for many connections
00:18 < BlueMatt> you also cant request missing txn since they are no longer in mempool [...]
00:21 < gmaxwell> sounds like we really do need a protocol extension for this.
[...] 00:23 < sipa> gmaxwell: i don't see how to do it without extra roundtrip
00:23 < BlueMatt> send a list of txn in your mempool (or bloom filter over them or whatever)!如摘录中所述,简单地扩展协议以支持发送用于请求交易的单个交易哈希以及区块中的单个交易,最终使得紧凑区块方案变得更加简单、抗DoS 和更高效。
进一步阅读资源
- https://people.xiph.org/~greg/efficient.block.xfer.txt
- https://people.xiph.org/~greg/lowlatency.block.xfer.txt
- https://people.xiph.org/~greg/weakblocks.txt
- https://people.xiph.org/~greg/mempool_sync_relay.txt
- https://en.bitcoin.it/wiki/User:Gmaxwell/block_network_coding
- http://diyhpl.us/~bryan/irc/bitcoin/block-propagation-links.2016-05-09.txt
- http://diyhpl.us/~bryan/irc/bitcoin/weak-blocks-links.2016-05-09.txt
- http://diyhpl.us/~bryan/irc/bitcoin/propagation-links.2016-05-09.txt